예제 코드 최종
indeed.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=java+spring&as_phr=&as_any=&as_not=&as_ttl=&as_cmp=&jt=all&st=&salary=&radius=25&l=%EA%B2%BD%EA%B8%B0%EB%8F%84+%EC%84%B1%EB%82%A8&fromage=any&limit={LIMIT}&sort=&psf=advsrch&from=advancedsearch"
def get_last_page():
result = requests.get(URL)
#모든 html 결과 가져오기
#print(indeed_result.text)
#Extract data from html
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div",{"class":"pagination"})
# print(pagination)
links = pagination.find_all("a")
# print(pages)
# link.find("span")
pages = []
for link in links[0:-1]:
pages.append(int(link.string))
# print(spans[:-1])
max_page = pages[-1]
return max_page
def extract_job(html):
#title
title = html.find("h2", {"class":"title"}).find("a")["title"]
#company
company = html.select_one("div.sjcl span.company")
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
#location
#location = html.select_one("span.location")
location = html.find("span",{"class":"location"}).string
#job_id
job_id = html["data-jk"]
return {"title":title, "company":company, "location":location, "link":f"https://kr.indeed.com/viewjob?jk={job_id}&from=serp&vjs=3"}
def extract_jobs(last_pages):
jobs = []
for page in range(last_pages):
print(f"Scrapping Indeed: Page: {page}")
url_text = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(url_text.text, "html.parser")
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
|
cs |
마지막 페이지를 구하는 get_last_page() 함수, last_page를 인자로 받아서 모든 페이지에서 모든 직업을 추출하는 extract_jobs()함수, 이 함수 안에서 직업추출 기능을 하는 extract_job() 함수 세가지로 정리된다.
52행에 보다 시피 리턴되는 job의 형태는 dictionary 이며, 키는 title, company, location, link로 구성된다.
궁금증 1
61행에서 find_all로 추출한 results는 62행에서 for result in results: 형태로 사용이 가능한데 반해,
20행에서 똑같이 find_all로 추출한 결과값 links를 25행에서는 for link in links[0:-1]: 형태로 사용하는지 궁금하다.
만약 links[0:-1] 형태가 아닌 links로만 할 경우

이런 에러가 발생한다.
아직 에러 발생 이유를 알지 못했다 ㅠㅠㅠ
so.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
import requests
from bs4 import BeautifulSoup
URL = "https://stackoverflow.com/jobs?q=java"
def get_last_page():
html_text = requests.get(URL)
soup = BeautifulSoup(html_text.text, "html.parser")
html_pages = soup.find("div",{"class":"s-pagination"}).find_all("a")
pages = []
for page in html_pages[0:-1]:
pages.append(page.find("span").string)
last_page = int(pages[-1])
return last_page
def extract_jobs(last_page):
for page in range(last_page):
print(f"Scrapping SO: Page:{page+1} 출력")
html_text = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(html_text.text,"html.parser")
htmls = soup.find_all("div",{"class":"-job"})
jobs=[]
for html in htmls:
job = extract_job(html)
jobs.append(job)
return jobs
def extract_job(html):
# title
title = html.find("h2",{"class":"mb4"}).find("a")["title"]
# company and location
company_row = html.find("h3",{"class":"fc-black-700"})
company, location = company_row.find_all("span", recursive=False)
company = str(company.string).strip()
location = str(location.string).strip()
# company.get_text(strip=True)
# location.get_text(strip=True)
# link
data_jobid = html["data-jobid"]
return {"title":title,"company":company, "location":location, "link":f"https://stackoverflow.com/jobs/{data_jobid}/"}
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
|
cs |
2021/02/17 기준 stackoverflow의 직업을 추출한 코드이다. 페이지의 html이 지속적으로 변화해서 이 코드도 nomad강의에서 실행한 코드와 다르다. 위에서 추출한 indeed.py와 코드 로직은 똑같다. 단지 40행의 recursive에 주목하자.
company, location = company_row.find_all("span", recursive=False)
span안에 span이 있는경우 모든 span을 다찾을 수 있다. recursive=False로 이를 방지하자.
그리고 우리가 span이 2개만 있다는 것을 알 수 있는 경우에 company, location = 이런식으로 직접 2개의 변수에 값을 저장할 수 있다.
main.py
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
save_to_file(jobs)
|
cs |
save.py
|
1
2
3
4
5
6
7
8
9
|
import csv
def save_to_file(jobs):
file = open("jobs.csv",mode="w", encoding="utf-8")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "link"])
for job in jobs:
writer.writerow(list(job.values()))
return
|
cs |
csv (comma separated values)
파이썬에서 제공하는 패키지 csv 활용
4행: w: 쓰기로만 파일을 열었다.
5행: writer = csv.writer(file) // 파일을 우리가 연 파일에다가 csv를 작성해준다.
6행, 8행: writer.writerow(리스트) // csv값 리스트로 값 추가
job.values()는 딕셔너리의 값들로만 추출하는 것이다. (키가 아닌)
결과
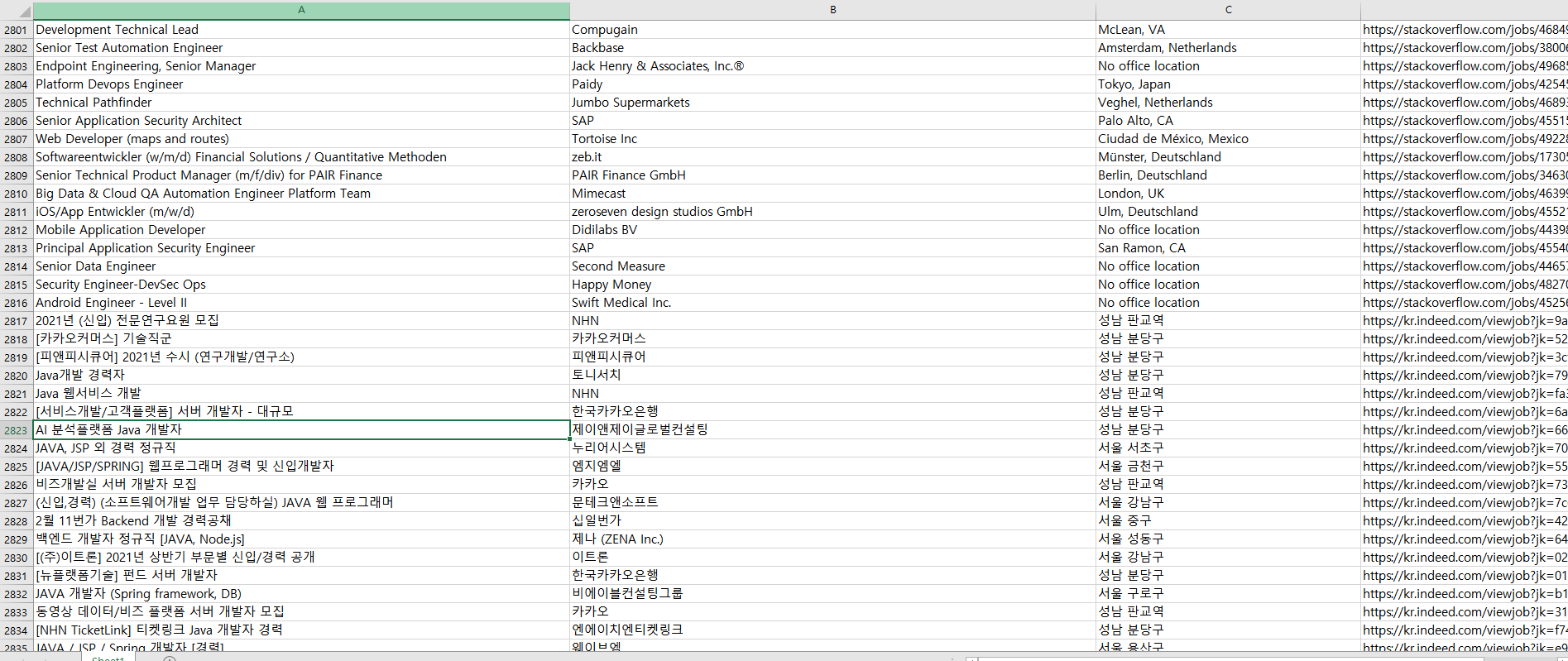
잘 추출된 모습이다 ~!
+추가적으로
repl.it 에서 로컬로 다운받고 싶을 수 있다.
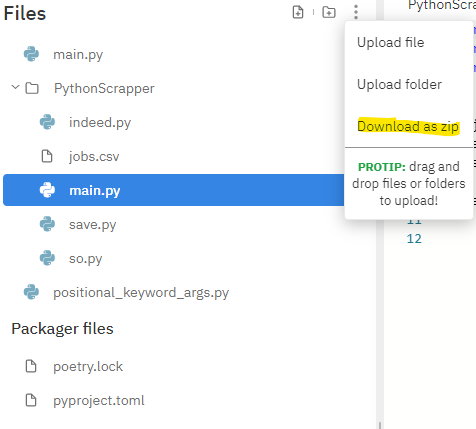
... 모양의 버튼을 누루고 Download as zip 버튼을 눌러 로컬에 다운받자 !!
Replit 에서 사용한 패키지 로컬에서 다운받는 방법 !!
Cmd 관리자 권한으로 열기
python -m pip install --upgrade pip
python -m pip install requests
python -m pip install beautifulsoup4
명령문을 실행한다. pip 버전이 맞다면 첫번째 명령문은 실행하지 않아도 된다.
import 해주기
import requests
import beautifulsoup4
rep.it에서 사용했던 코드처럼 import를 활용하자